Data Serialization - JSON, BSON, MessengePack, Protocol Buffer, Thrift, Avro, Cap’n Proto, FlatBuffers
Overview
According to Wikipedia, serialization is:
Serialization is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment).
Serialization is a pervasive activity in a lot programs, and a common source of memory inefficiency, with lots of temporary data structures needed to parse and represent data, and inefficient allocation patterns and locality.
There are several classic data serialization formats, such as JSON, XML, CVS/TVS, Python Pickle, et. Among them, JSON is the most popular format for data serialization, and it has the following features (from this post):
- (Mostly) human readable code, similar to XML/CSV/TSV format.
- Very simple and straightforward specification.
- Widespread support: not only does every programming language or IDE come with JSON support, but also many web services APIs offer JSON as a means of data interchange.
As people utilize more complex architecture, serialization must meets several requirements: flexibililty, ability to grow, latency and still stay simple. This is when the drawbacks of classic formats start to hurt:
- lack of strict protocol description
- you have to maintain both server and client side code
- the size of human-readable files are larger than binary files
- lack of backward/forward compatibility
This article is going to introduce some wildly used binary data serialization formats:
| Formats | Features |
|---|---|
| BSON, MessagePack |
- Do not require 'Schema' or compiling - easy to use - Best drop-in replacements if JSON is already used - have simple to implement specifications - less space efficient |
| Protocol Buffer, Thrift | - mature and wilely used systems - best support for multiple languags and cross platform - accompanied by good RPC frameworks: gRPC/Thrift |
| Apache Avro |
- associated with hadoop/spark ecosystem - no compile stage because schema is embedded in the header of messages - use JSON as IDL to describe message format |
| Cap’n Proto, FlatBuffers |
- evolutions of protobuf/thrift - require no encoding/decoding stage - suitable for mobile/game/VR applications |
Data Formats
BSON
BSON, short for Binary JSON, is best known as the primary data representation for MongoDB. It is designed for fast in-memory manipulation and support in-place updating.
MessagePack
MessagePack (MsgPack) is effectively JSON, but with efficient binary encoding. Like JSON, there is no or schemas, which depending on your application can be either be a pro or a con. But, if you are already streaming JSON via an API or using it for storage, then MessagePack can be a drop-in replacement. With a simple specification, MessagePack is supported by over 50 programming languages and environments.
MessagePack is originally designed for network communication while BSON is designed for storages. As MessagePack’s format is less verbose than BSON, MessagePack has smaller encoded file than BSON. As a result, MsgPack is also an extremely good methods to send small messages on wire. Besides, MsgPack has RPC support, static type-checking APIs and streaming APIs.
Protocol Buffer
Protocol Buffer (Protobuf) was originally designed by Google at around 2001, and the second version (proto2) has been open-sourced since 2008. As of today, Protobuf is not only the glue to all Google services, but also an battle tested, very stable, well trusted system.
The typical steps of using Protobuf is like: When you run the protocol buffer compiler on a .proto, the compiler generates the code in your chosen language you’ll need to work with the message types you’ve described in the file, including getting and setting field values, serializing your messages to an output stream, and parsing your messages from an input stream.
Protocol Buffers language version 3 (aka proto3) was released at Jul 2016, which is not compatible to previous version. Proto3 simplifies the protocol buffer language, both for ease of use and to make it available in a wider range of programming languages: our current release lets you generate protocol buffer code in Java, C++, Python, Java Lite, Ruby, JavaScript, Objective-C, and C#.
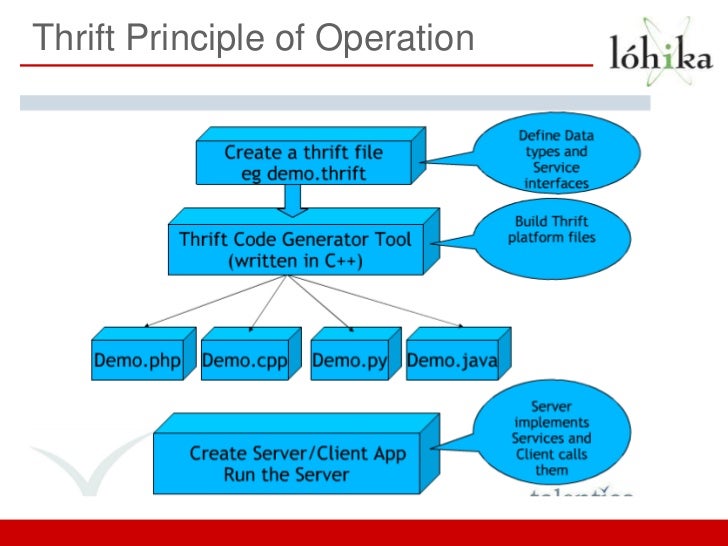
Apache Thrift
Apache Thrift was first designed internally by Facebook and donated to Apache Foundation afterwards. It has a data serialization format similar to Protobuf, as well as a build-in RFC (remote procedure call) framework.
Thrift is good at building services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml and Delphi and other languages.
Apache Avro
Apache Avro is a language-neutral data serialization system. The project was created by Doug Cutting (the creator of Hadoop) to address the major downside of Hadoop Writables: lack of language portability.
Avro provides functionality similar to systems such as Thrift, Protocol Buffers, etc. Avro differs from these systems in the following fundamental aspects:
- Avro data is described using a language-independent schema. However, unlike in the other systems, code generation is optional in Avro, which means you can read and write data that conforms to a given schema even if your code has not seen that particular schema before. To achieve this, Avro assumes that the schema is always present at both read and write time. Avro schemas are defined with JSON . This facilitates implementation in languages that already have JSON libraries.
- Dynamic typing: Avro does not require that code be generated. Data is always accompanied by a schema that permits full processing of that data without code generation, static datatypes, etc. This facilitates construction of generic data-processing systems and languages.
- Untagged data: Since the schema is present when data is read, considerably less type information need be encoded with data, resulting in smaller serialization size.
- No manually-assigned field IDs: When a schema changes, both the old and new schema are always present when processing data, so differences may be resolved symbolically, using field names.
Apache Avro supports languages like C, C++, C#, Go, Haskell, Java, Perl, PHP, Python, Ruby, Scala. What’s more important, it works really well with Apache Hadoop/Spark ecosystem.
Cap’n Proto
Cap’n Proto is an fast data interchange format and capability-based RPC system. The main selling point of Cap’n Proto is that there is no encoding/decoding step. In other words, Cap’n Proto has the ability to read data without first unpacking it. It is primarily created at around 2014 by Kenton Varda, who was the primary author of Protocol Buffers version 2, which is the version that Google released open source.
FlatBuffers
FlatBuffers is an open source project from Google created mainly by Wouter van Oortmerssen. It is an evolution of protocol buffers that includes object metadata. FlatBuffers follows similar design principles to Cap’n Proto, which is that data should be structured the same way in-memory and on the wire, thus avoiding costly encode/decode steps.
No matter how similar they are, there is one scenario where flatbuffers handles better than Cap’n Proto: FlatBuffers, like Protobuf, has the ability to leave out arbitrary fields from a table (better yet, it will automatically leave them out if they happen to have the default value). as data evolves, cases where lots of field get added/removed, or where a lot of fields are essentially empty are extremely common, making this a vital feature for efficiency, and for allowing people to add fields without instantly bloating things.
In particular, FlatBuffers focus is on mobile hardware (where memory size and memory bandwidth is even more constrained than on desktop hardware), and applications that have the highest performance needs: games. Facebook has this awesome post about how they improved Facebook’s performance on Android with FlatBuffers.